
Trong phân tích dữ liệu, hàm LAG() và LEAD() sẽ là công cụ hỗ trợ đắc lực cho việc so sánh giá trị hiện tại với giá trị liền trước hoặc liền sau là điều thường xuyên xảy ra từ theo dõi xu hướng doanh thu, hành vi người dùng, đến hiệu suất hệ thống. Dù đơn giản, hai hàm này giúp bạn dễ dàng truy xuất dữ liệu từ dòng trước hoặc sau trong bảng, mà không cần viết truy vấn phức tạp hay sử dụng nhiều phép JOIN. Đây là công cụ cực kỳ hữu ích để xử lý dữ liệu có tính thứ tự.
UniTrain sẽ giúp bạn hiểu rõ cách dùng qua ví dụ thực tế và ứng dụng trong công việc.
HÀM LAG
Hàm LAG() cho phép lấy giá trị từ dòng trước đó trong kết quả truy vấn. Tên gọi của hàm cũng thể hiện rõ chức năng của nó – “lùi lại phía sau”.
Cú pháp:
LAG(expression [, offset [, default]]) OVER (
[PARTITION BY partition_expression, …]ORDER BY sort_expression [ASC | DESC], …)
- expression: Là cột hoặc giá trị bạn muốn lấy.
- offset: Tham số tùy chọn, chỉ định số dòng phía sau dòng hiện tại mà bạn muốn xem. Nếu không ghi rõ, mặc định là 1.
- default: Tham số tùy chọn, giá trị trả về khi hàm LAG() cố gắng truy cập vượt ra ngoài dòng đầu tiên. Nếu không chỉ định, giá trị mặc định là NULL.
- PARTITION BY: Chia tập kết quả thành các phần (phân vùng), và hàm LAG() chỉ hoạt động trong mỗi phân vùng riêng biệt.
- ORDER BY: Xác định thứ tự của các dòng trong tập kết quả hoặc từng phân vùng.
Giống như các hàm khác, LAG() yêu cầu phải có mệnh đề OVER. Mệnh đề này có thể nhận các tham số tùy chọn, sẽ được giải thích sau. Với LAG(), bạn bắt buộc phải chỉ định ORDER BY trong mệnh đề OVER, với một cột hoặc danh sách các cột để xác định thứ tự sắp xếp các dòng.
Ví dụ chúng ta có một bảng chi tiết đơn hàng (SalesOrderDetail) thể hiện doanh thu của từng dòng đơn hàng:
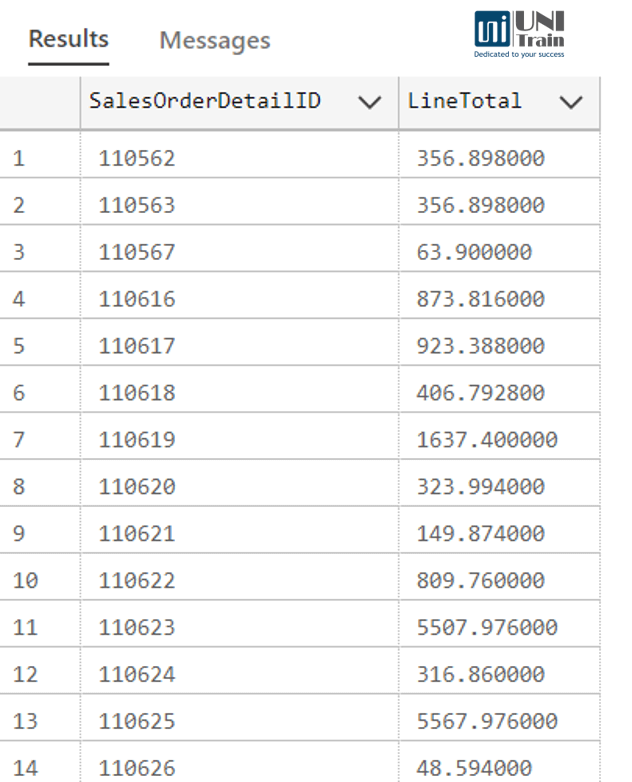 Mục tiêu của chúng ta là phân tích sự biến động doanh thu giữa các dòng đơn hàng liền kề. Cụ thể, chúng ta muốn tính xem xét, so sánh doanh thu qua các đơn hàng:
Mục tiêu của chúng ta là phân tích sự biến động doanh thu giữa các dòng đơn hàng liền kề. Cụ thể, chúng ta muốn tính xem xét, so sánh doanh thu qua các đơn hàng:
SalesOrderDetailID,
LineTotal,
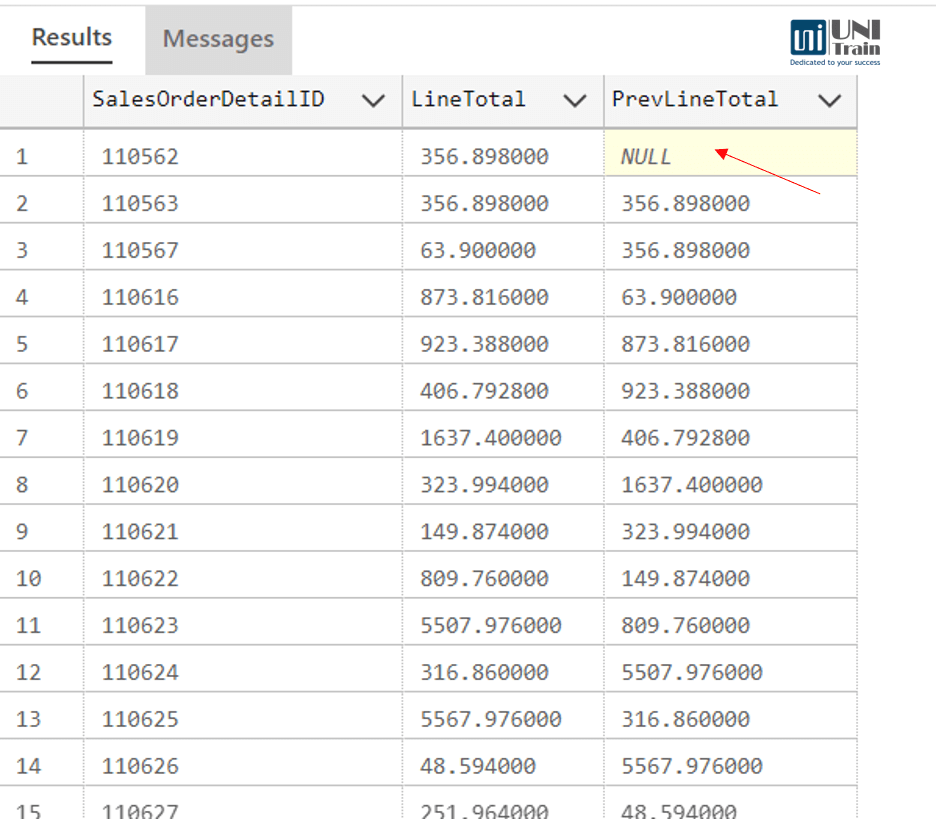
LAG(LineTotal)
OVER (ORDER BY SalesOrderDetailID) AS PrevLineTotal
FROM
SalesLT.SalesOrderDetail;
Kết quả
HÀM LEAD
Hàm LEAD() là sẽ ngược lại với hàm LAG(). Nó cho phép bạn lấy giá trị từ dòng tiếp theo trong tập kết quả — tức là nhìn trước một hoặc nhiều dòng trong dữ liệu.
Cú pháp hàm LEAD:
OVER (
[PARTITION BY partition_expression, … ] ORDER BY sort_expression [ASC | DESC], …)
- expression: Cột hoặc biểu thức bạn muốn lấy từ dòng tiếp theo.
- offset (tuỳ chọn): Số dòng muốn nhìn tới (mặc định là 1 dòng kế tiếp).
- default (tuỳ chọn): Giá trị trả về nếu dòng kế tiếp không tồn tại.
- OVER(…): Bắt buộc, xác định cách sắp xếp và (nếu cần) phân vùng dữ liệu.
Tương tự với bảng dữ liệu trên:
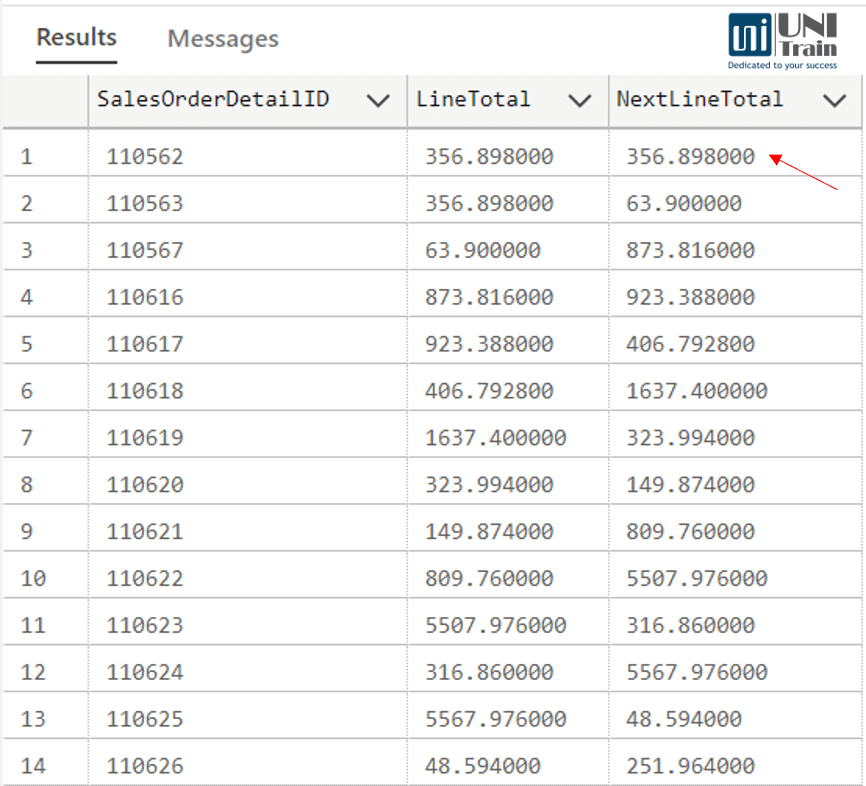
Muốn xác định tổng doanh thu (LineTotal) của dòng đơn hàng kế tiếp, so với từng dòng hiện tại. Cụ thể, bạn đang truy xuất thông tin “tương lai gần” trong tập dữ liệu – tức giá trị kế tiếp theo thứ tự SalesOrderDetailID.
SalesOrderDetailID,
LineTotal,
LEAD(LineTotal) OVER (ORDER BY SalesOrderDetailID) AS NextLineTotal
FROM
SalesLT.SalesOrderDetail;
Kết quả truy vấn:
Kết luận
Hàm LAG() và LEAD() là hai công cụ rất hữu ích trong phân tích dữ liệu, giúp truy xuất nhanh chóng giá trị của dòng liền trước hoặc liền sau mà không cần viết các truy vấn phức tạp hay dùng nhiều phép JOIN. Chúng đặc biệt hiệu quả khi làm việc với dữ liệu có tính thứ tự hoặc dữ liệu phân vùng, cho phép bạn dễ dàng so sánh, phân tích xu hướng, biến động hay dự báo dựa trên các giá trị liền kề trong bảng.
Việc sử dụng linh hoạt hàm LAG() và LEAD() sẽ giúp tối ưu quá trình xử lý dữ liệu, tiết kiệm thời gian và tăng tính chính xác trong phân tích, từ đó hỗ trợ đưa ra quyết định nhanh chóng và hiệu quả trong công việc.
Theo dõi Fanpage UniTrain để khám phá thêm nhiều thông tin hữu ích nhé.
Xem thêm
Ứng dụng SQL trong xử lý dữ liệu



