
Tiếp nối với phần 1, hãy cùng UniTrain tiếp tục tìm hiểu một số hàm Pandas thông dụng trong Python dành cho Data Analyst nhé!
Các hàm chúng ta sẽ cùng tìm hiểu hôm nay có chức năng:
– Cung cấp một cái nhìn chi tiết hơn về bộ dữ liệu
– Thay đổi một số yếu tố trong bảng dữ liệu
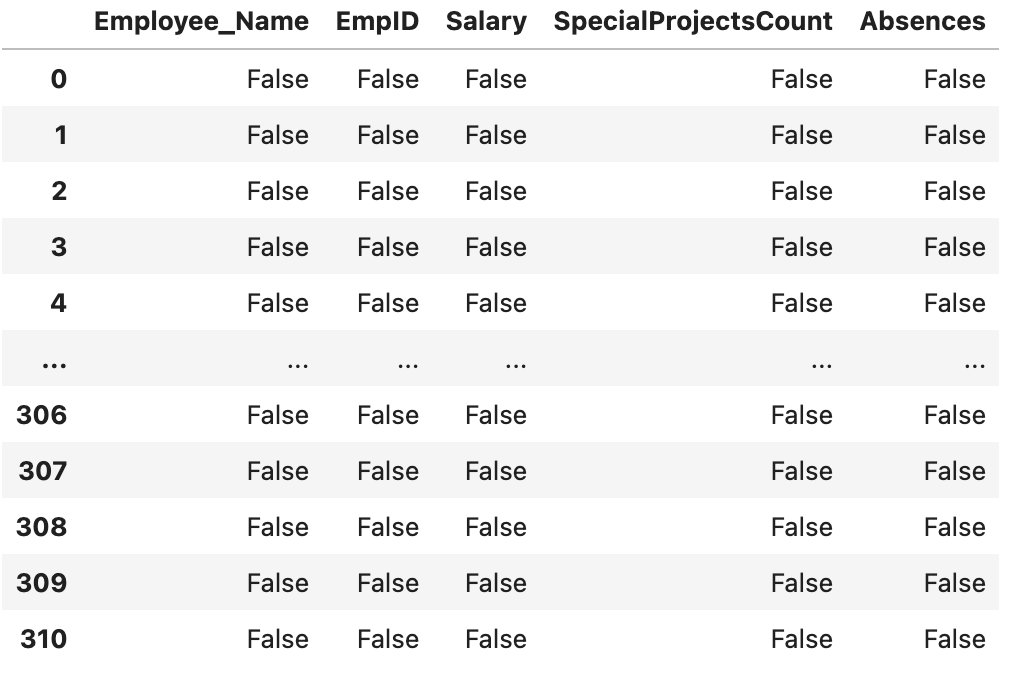
df.isnull()
Hàm này giúp ta kiểm tra xem dữ liệu có giá trị thiếu hay không. Khi giá trị tại một vị trí bị thiếu, df.isnull() trả về True cho vị trí đó và False cho tất cả các vị trí khác.
df.isnull()
df.sort_values()
Hàm này cho phép bạn sắp xếp lại các hàng trong một DataFrame theo giá trị của một cột cụ thể, theo thứ tự tăng dần hoặc giảm dần.
Giả sử chúng ta cần sắp xếp lương của nhân viên theo thứ tự tăng dần, ta làm như sau:
df.sort_values(“Salary”)
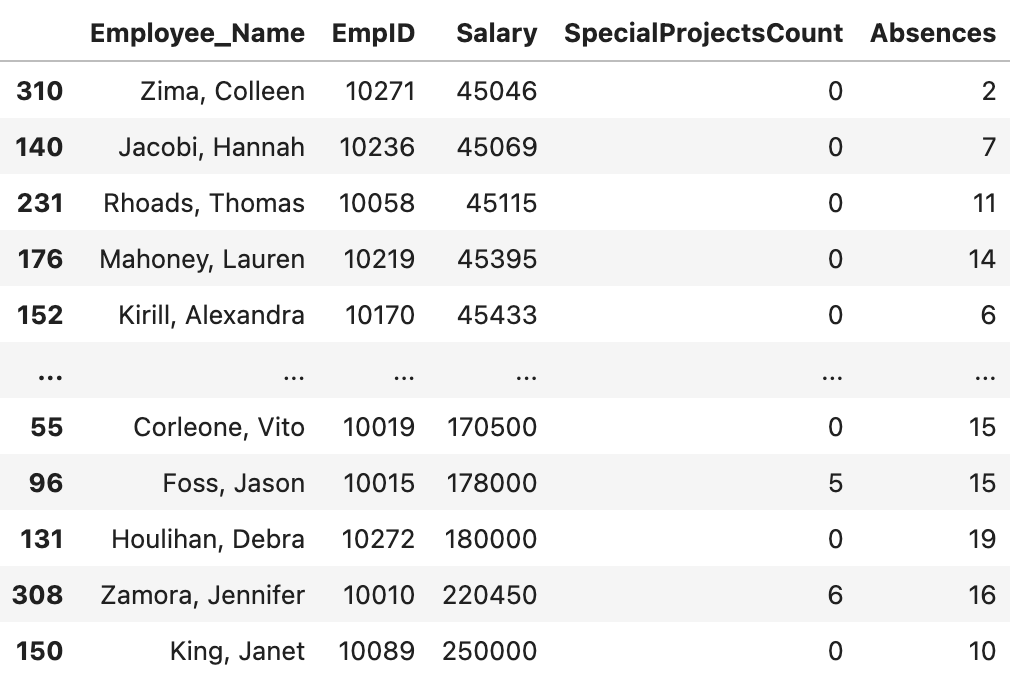
Theo mặc định, hàm này sẽ trả về kết quả theo thứ tự tăng dần, (ascending=True), để sắp xếp các giá trị theo thứ tự giảm dần (ascending=False), chúng ta làm như sau:
df_sorted_descending = df.sort_values(by=’Salary’, ascending=False)
df_sorted_descending
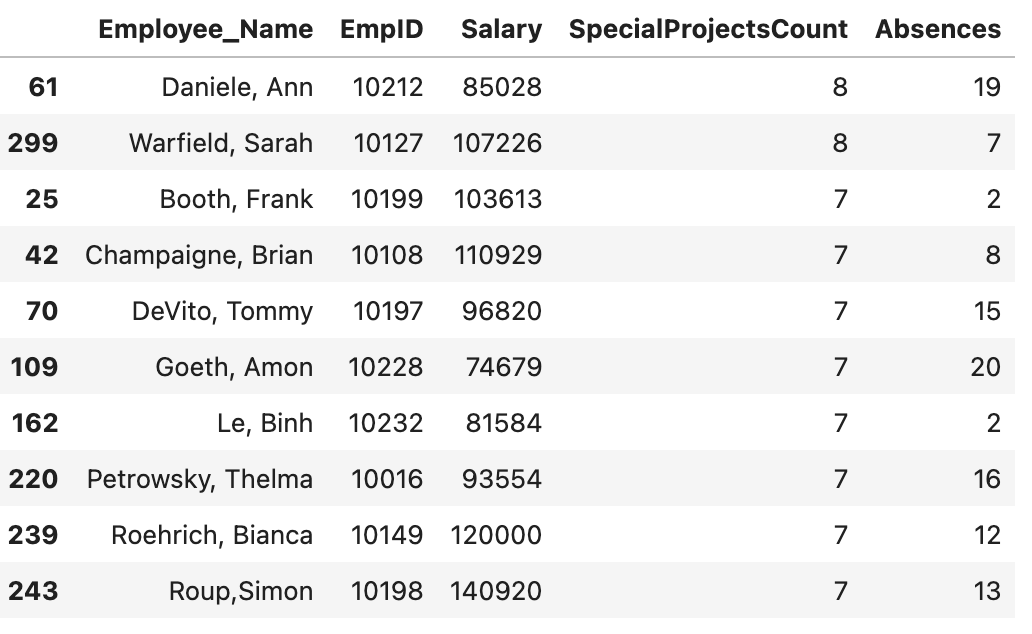
df.nlargest()
Hàm này giúp truy xuất một số giá trị lớn nhất từ một cột cụ thể của DataFrame và tất cả các hàng chứa giá trị đó.
Giả sử chúng ta cần lấy ra thông tin của 10 nhân viên với SpecialProjectsCount lớn nhất, chúng ta làm như sau:
df.nlargest(10, “SpecialProjectsCount”)
df.nsmallest()
Hàm này giúp truy xuất một số giá trị nhỏ nhất từ một cột cụ thể của DataFrame và tất cả các hàng chứa giá trị đó.
Giả sử chúng ta cần lấy ra thông tin của 10 nhân viên với SpecialProjectsCount nhỏ nhất, chúng ta làm như sau:
df.nsmallest(10, “SpecialProjectsCount”)
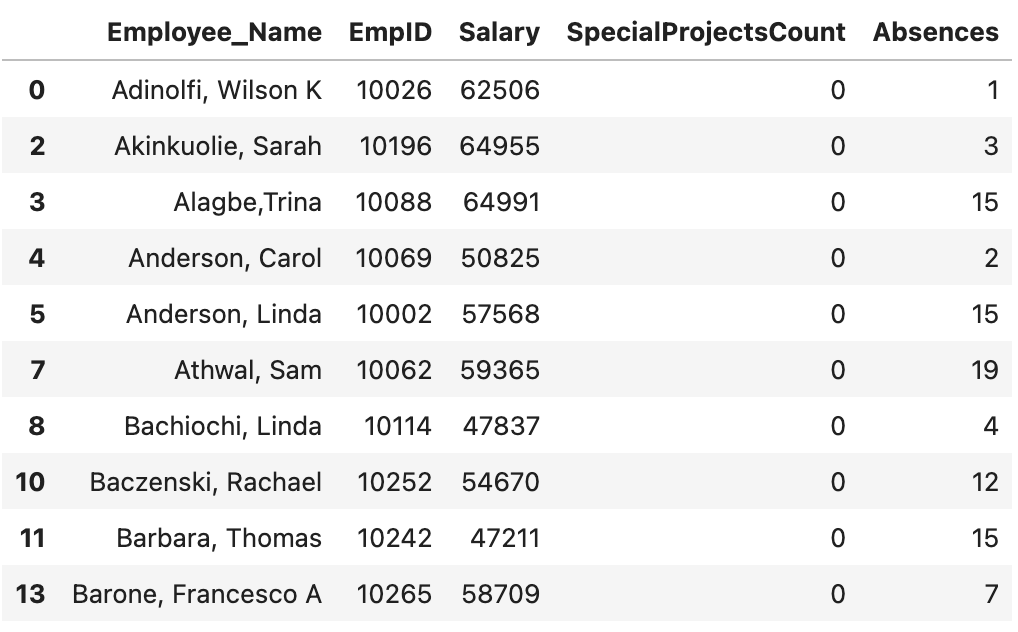
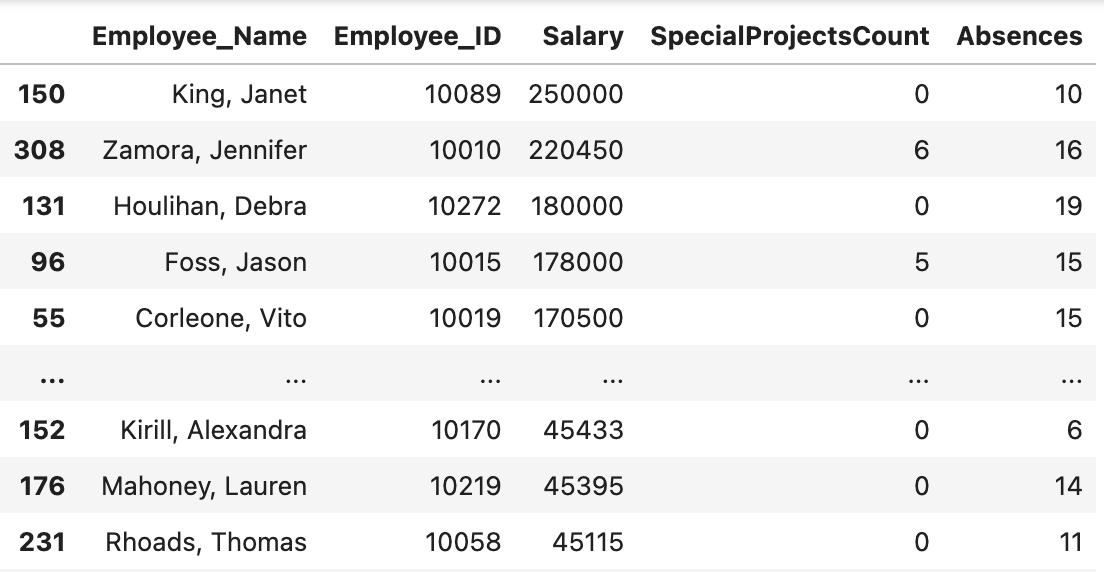
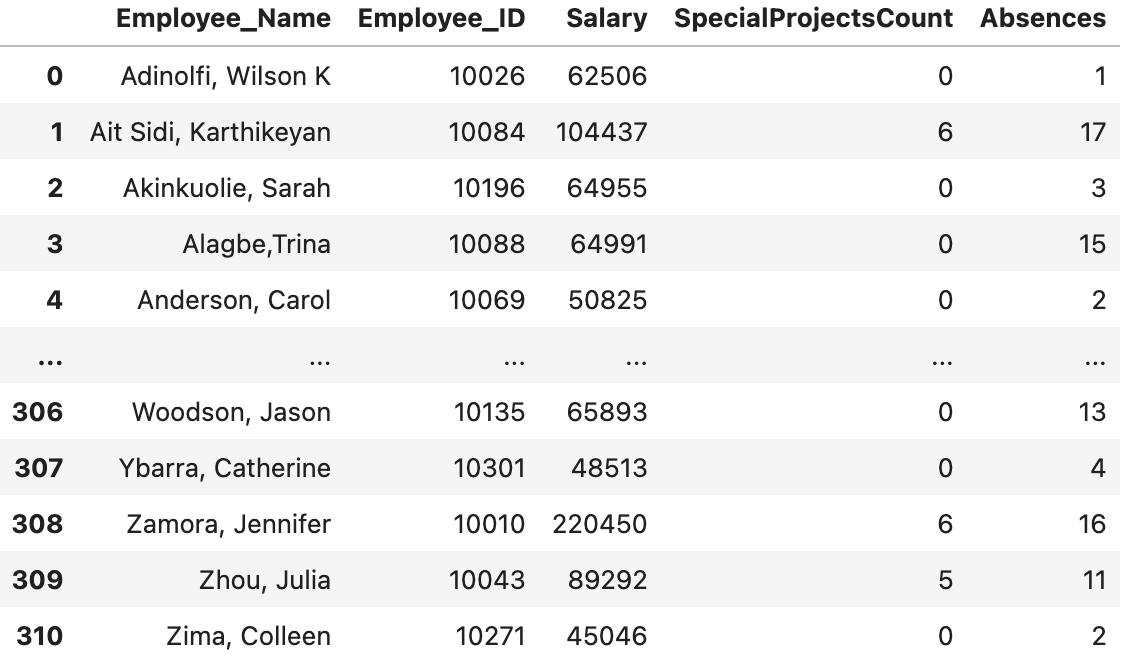
df.rename()
Hàm này giúp chúng ta thay đổi tên của một hay nhiều cột.
Giả sử chúng ta cần đổi tên cột “EmpID” sang “Employee_ID”, chúng ta làm như sau:
df.rename(columns = {“EmpID”: “Employee_ID”},
inplace=True)
df
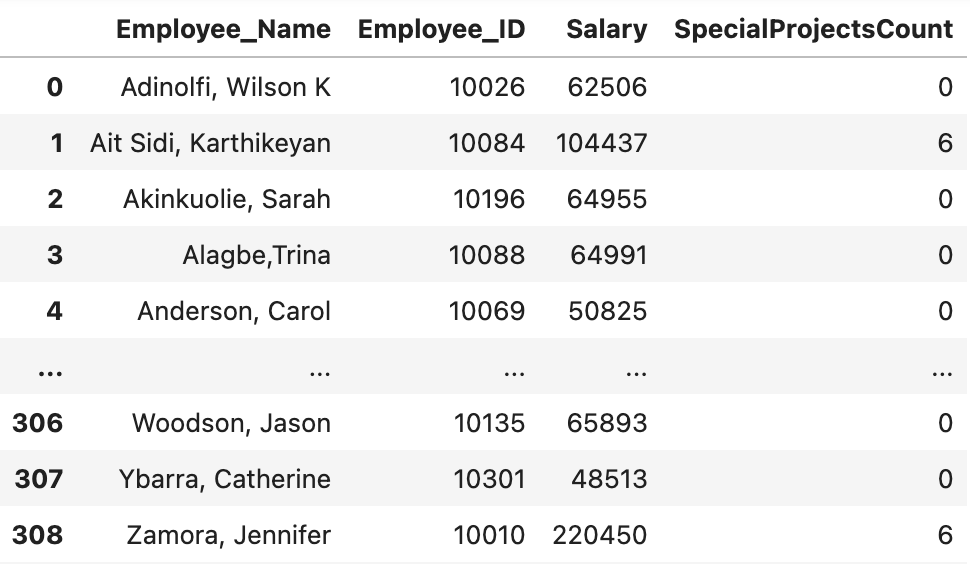
df.drop()
Hàm này giúp chúng ta xóa một hay nhiều hàng, cột hoặc nhãn khỏi DataFrame.
Giả sử chúng ta cần xóa cột “Absences”, ta làm như sau:
df.drop(“Absences”, axis=1)
Xem thêm:
Các hàm Pandas thông dụng dành cho Data Analyst (Phần 1)
Trực quan hóa dữ liệu với Python
Khóa học Xử lý và Trực quan hóa dữ liệu với Python



