Phân loại dữ liệu là gì?
Phân loại dữ liệu có nghĩa là xác định dữ liệu theo loại, độ nhạy, nơi lưu trữ và giá trị của nó đối với công ty. Phân loại đúng dữ liệu là điều cơ bản để doanh nghiệp có thể bảo vệ dữ liệu nhạy cảm khi chia sẻ với các nhân viên và đối tác.
Theo một báo cáo năm 2021 của IBM, chỉ ra rằng các vi phạm dữ liệu ngày nay khiến các công ty phải trả trung bình 4,24 triệu đô la cho mỗi sự cố.
Khi bạn phân loại các loại dữ liệu đang được lưu trữ, bạn sẽ có thể xác định chính xác mức độ bảo mật cần thiết và đưa ra phương hướng giải quyết vấn đề xâm phạm dữ liệu.
Mục đích của phân loại dữ liệu
– Giảm thiểu rủi ro: Giới hạn, kiểm soát quyền truy cập.
– Quản trị: Xác định dữ liệu được điều chỉnh bởi GDPR, HIPAA, CCPA. Theo dõi, kiểm soát và bổ sung dữ liệu. Cho phép lưu giữ hợp pháp và các hoạt động theo quy định khác của công ty.
– Tối ưu hóa hiệu quả: Khám phá và loại bỏ dữ liệu cũ dư thừa. Chuyển dữ liệu được sử dụng nhiều sang thiết bị với hiệu năng tốt hơn hoặc sang đám mây để dễ dàng truy cập.
– Phân tích: cách sử dụng dữ liệu và ý nghĩa của chúng đối với hoạt động kinh doanh.
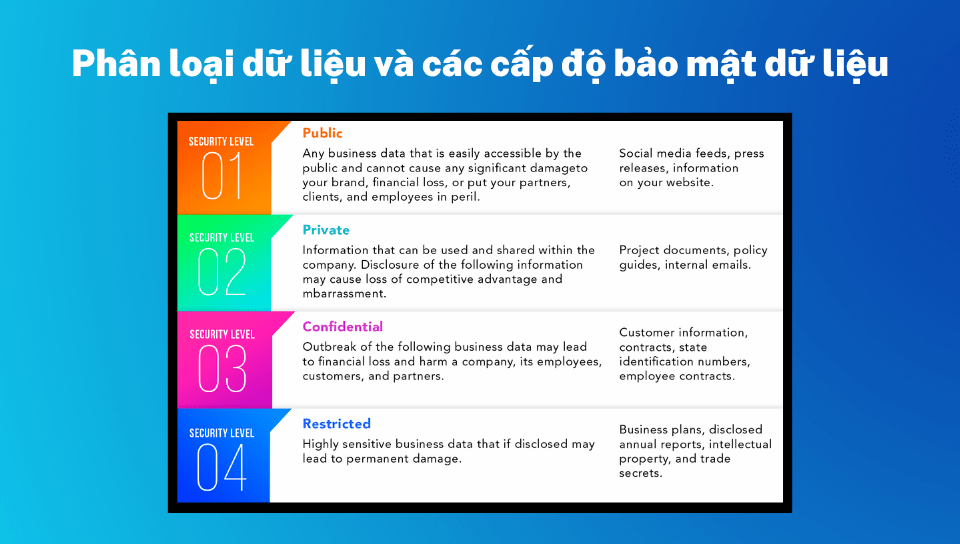
Các cấp độ bảo mật của dữ liệu

Cấp 1: Public
Đây là loại dữ liệu được công khai, có thể truy cập dễ dàng bởi bất kỳ một người nào trong công ty. Và cũng vì điều đó, loại dữ liệu này không có giá trị quá lớn đối với doanh nghiệp. Trong trường hợp bị đánh cắp, không gây thiệt hại nhiều đối với doanh nghiệp và các đối tác của họ.
Cấp 2: Private
Đây là loại dữ liệu không công khai, được lưu truyền trong nội bộ công ty. Nó có thể gây ra một số thiệt hại và đánh mất danh tiếng nếu bị lộ ra. Tuy nhiên, thiệt hại chỉ ở mức độ cơ bản, không đến mức đánh vào yếu điểm của hoạt động kinh doanh.
Cấp 3: Confidential
Với mức độ bảo mật cao hơn “Private”, đây là loại dữ liệu có vai trò quan trọng đối với doanh nghiệp. Công ty sẽ bị thiệt hại nặng về tài chính và gây bất lợi cho đối tác, khách hàng nếu những thông tin này bị đánh cắp.
Cấp 4: Restricted
Loại dữ liệu với mức độ nhạy cảm cao nhất, nếu bị rò rỉ ra ngoài sẽ gây ra thiệt hại vĩnh viễn đối với công ty.
6 bước phân loại dữ liệu hiệu quả
#1. Xác định mục tiêu
Để xác định rõ mục tiêu, các doanh nghiệp cần trả lời các câu hỏi sau:
– Doanh nghiệp phân loại dữ liệu để làm gì?
– Cần tuân thủ theo quy định nào không?
– Có các mục tiêu kinh doanh khác cần giải quyết không? (giảm thiểu rủi ro, tối ưu kho lưu trữ,…)
#2. Phân loại kiểu dữ liệu
– Xác định loại dữ liệu mà tổ chức tạo ra (ví dụ: danh sách khách hàng, hồ sơ tài chính,..)
– Phân định dữ liệu độc quyền so với dữ liệu công khai.
#3. Thiết lập các mức phân loại
– Công ty cần bao nhiêu cấp độ phân loại?
– Ghi chú lại từng cấp độ và cung cấp các ví dụ.
#4. Xác định quy trình phân loại tự động
– Xác định cách ưu tiên để quét dữ liệu
– Thiết lập tần suất và tài nguyên dùng để phân loại dữ liệu tự động
#5. Xác định phân loại và tiêu chí để phân loại
– Xác định các tệp dữ liệu được bảo mật cao
– Thiết lập một quy trình để xem xét và các thực các kết quả được phân loại
#6. Xác định kết quả và cách sử dụng dữ liệu được phân loại
– Các bước giảm thiểu rủi ro và chính sách tự động
– Xác định quy trình ấp dụng phân tích cho kết quả phân loại
– Thiết lập kết quả mong từ phân tích
#7. Giám sát và bảo trì
– Thiết lập quy trình làm việc liên tục để phân loại dữ liệu mới hoặc dữ liệu đã cập nhật
– Đánh giá lại quá trình phân loại và cập nhật nếu cần thiết
Kết luận
Phân loại dữ liệu là biện pháp giúp cho doanh nghiệp tránh khỏi trường hợp bị đánh cắp thông tin kinh doanh quan trọng, bằng cách phân loại tệp dữ liệu chung ra từng nhóm nhỏ. Thực hiện bảo vệ và hạn chế quyền truy cập đối với những nhóm dữ liệu quan trọng, độ bảo mật cao. Tối ưu hóa công việc kinh doanh và giảm thiểu rủi ro cho doanh nghiệp và các đối tác liên quan.
Xem thêm
Hàm Excel nâng cao dành cho cơ sở dữ liệu
Làm thế nào để xác thực dữ liệu trong Excel
Combo Khóa học: Business Intelligence



