
Thiếu dữ liệu (Missing Data) là gì?
Đúng với tên gọi của nó, dữ liệu bị thiếu là dữ liệu không đầy đủ, không thể thực hiện phân tích dữ liệu được. Do nhiều nguyên nhân:
– Người thu thập dữ liệu quên điền
– Không có đủ dữ liệu ở các nguồn và sơ đồ cấp
– Dữ liệu bị mất trong quá trình chuyển đổi thủ công từ cơ sở dữ liệu cũ
– Lỗi chương trình
Các loại dữ liệu bị thiếu
Thiếu dữ liệu được phân thành 3 loại:
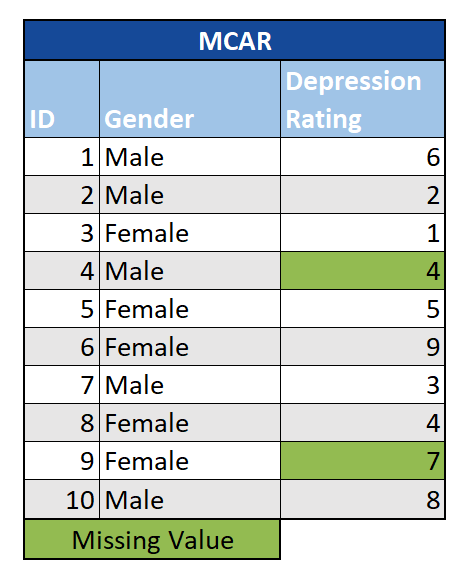
#1. Missing Complete At Random (Dữ liệu bị thiếu hoàn toàn ngẫu nhiên)
Trong trường hợp này, dữ liệu bị thiếu không phải do lỗi hệ thống hay sự bất cẩn của nhân sự trong khâu nhập dữ liệu, mà vì khi thực hiện thu thập dữ liệu từ các nguồn bên ngoài có sự khác nhau.
Ví dụ: Trong một cuộc khảo sát về mức độ trầm cảm dựa trên câu hỏi và thang đo. Những người tham gia khảo sát được hỏi những câu khác nhau trong các trường hợp khác nhau => Dẫn đến kết quả không đồng nhất, mặc dù hành vi là tương tự nhau.
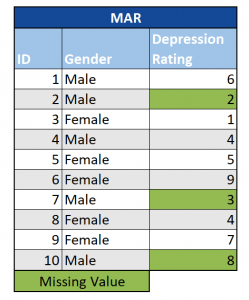
#2. Missing At Random (Dữ liệu bị thiếu ngẫu nhiên)
Khác với MCAR, MAR diễn ra do sự tác động của các biến trong nghiên cứu, chứ không phải nguyên nhân từ nguồn dữ liệu.
Ví dụ: Giả sử chúng ta biết rằng nam giới ít trả lời câu hỏi khảo sát về trầm cảm phụ nữ vì không liên quan đến giới tính của họ. Nên chắc chắn rằng họ bỏ qua hoặc trả lời bâng quơ khá đáng kể, dẫn đến dữ liệu bị thiếu. Điều này có thể coi là dữ liệu bị thiếu ngẫu nhiên.
#3. Missing Not At Random (Dữ liệu bị thiếu ngẫu nhiên)
Lấy ví dụ về làm mẫu, một người có mức độ trầm cảm đặc biệt cao từ chối trả lời khảo sát về mức độ trầm cảm, được coi là MNAR. Điều này dẫn đến dữ liệu bị thiếu mà không thể đưa vào phân tích (vì nó sai lệch).

Cách xử lý dữ liệu bị thiếu
Bỏ qua
Đơn giản là khi dữ liệu bị thiếu, nhân sự có thể hoàn toàn loại bỏ nó để thực hiện phân tích hoặc tìm kiếm một nguồn dữ liệu đầy đủ hơn.
Xóa
Xóa dữ liệu để tránh dẫn đến kết quả sai sót là một trong những cách thường được sử dụng nhất tại doanh nghiệp.
Bổ sung
Bên cạnh lấy trực tiếp từ nguồn dữ liệu, nhân sự hoàn toàn có thể tự bổ sung dữ liệu dựa trên dữ liệu đã được thu thập và kèm theo một số quy tắc cần tuân thủ.
Sau đây là một số quy tắc có thể áp dụng cho công việc bổ sung dữ liệu:
– Giá trị trung bình: Lấy vị trí khảo sát trầm cảm ở trên làm mẫu, nhân sự hoàn toàn có thể điền vào các ô còn thiếu bằng cách lấy trung bình các số chỉ ở các ô còn lại.
– Lấy tương tự: dựa trên một số đặc điểm tương đồng của đối tượng, nhân sự có thể lấy chỉ số của người này áp dụng cho người kia.
– Hồi quy tuyến tính: Bằng cách sử dụng giá trị dữ liệu liên quan, nhân sự có thể dự đoán giá trị dữ liệu bị thiếu.
Xem thêm
Làm thế nào để đưa ra quyết định sáng suốt dựa trên dữ liệu?
28 thuật ngữ Phân tích dữ liệu cho dân dữ liệu
Khóa học: COMBO 3 KHÓA PHÂN TÍCH DỮ LIỆU DÀNH CHO CHUYÊN GIA



