
Các hàm xếp hạng trong SQL đóng vai trò thiết yếu trong việc xác định thứ tự và vị trí tương đối của các bản ghi trong tập dữ liệu. Chúng không chỉ hỗ trợ truy vấn thông tin một cách linh hoạt mà còn giúp phát hiện những dữ liệu ẩn mà các phương pháp thông thường có thể bỏ sót. Bài viết này sẽ giúp bạn nắm vững cách sử dụng hàm RANK() và DENSE_RANK() trong SQL và biết cách ứng dụng chúng vào các bài toán thực tế trong phân tích dữ liệu.
HÀM RANK()
Hàm RANK() trong SQL được sử dụng để gán một thứ hạng cụ thể cho các dòng dữ liệu trong bảng dựa trên điều kiện sắp xếp nhất định. Mỗi bản ghi sẽ được đánh số thứ tự tương ứng với vị trí của nó trong tập dữ liệu đã được sắp xếp.
Khi xảy ra trường hợp có nhiều dòng cùng giá trị ở tiêu chí xếp hạng chính, RANK() sẽ xử lý bằng cách giữ nguyên thứ hạng cho các dòng đó, sau đó nhảy qua số thứ tự tương ứng ở các dòng tiếp theo. Cơ chế này cho phép hàm xử lý hiệu quả các dữ liệu trùng lặp và đảm bảo tính logic trong phân cấp dữ liệu.
Ví dụ điển hình cho việc sử dụng RANK() là xếp hạng nhân viên trong từng phòng ban theo mức lương, hoặc xác định vị trí của sinh viên dựa trên điểm số học tập. Kết quả trả về không chỉ giúp hình dung rõ ràng hơn về mối quan hệ thứ bậc giữa các bản ghi mà còn hỗ trợ ra quyết định trong những bối cảnh cần phân tích dữ liệu theo cấu trúc phân tầng.
Tóm lại, các hàm xếp hạng như RANK() là công cụ hữu ích để khai thác chiều sâu của dữ liệu, từ đó đưa ra các chiến lược xử lý phù hợp với từng tình huống nghiệp vụ.
Cú pháp hàm RANK():
SELECT
column1,
column2
RANK() OVER (
PARTITION BY partition_column1, partition_column2 ORDER BY order_column1 (ASC or DESC), order_column2 (ASC or DESC)
)
AS rank_column
FROM
table_name;
Tham số
- RANK(): Chính là hàm dùng để thực hiện việc xếp hạng.
- PARTITION BY: Mệnh đề tùy chọn dùng để chia tập kết quả thành các nhóm riêng biệt. Việc xếp hạng sẽ được thực hiện riêng trong từng nhóm. Nếu không sử dụng PARTITION BY, toàn bộ tập dữ liệu sẽ được xử lý như một nhóm duy nhất.
- ORDER BY: Mệnh đề này xác định cột (hoặc các cột) được sử dụng để sắp xếp dữ liệu, từ đó quyết định thứ tự xếp hạng.
Ví dụ có bảng nhân sự theo phòng ban và các mức lương như sau:
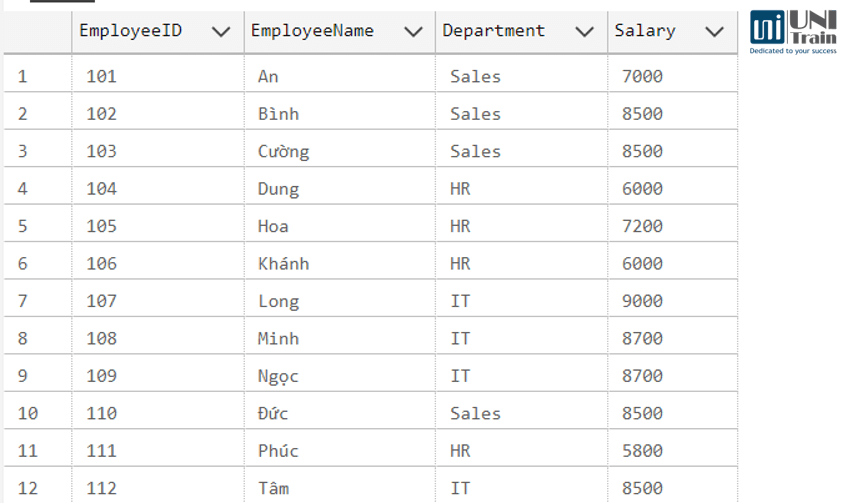
Để xếp hạng nhân viên theo mức lương trong từng phòng ban, bạn có thể sử dụng hàm RANK() kết hợp với PARTITION và ORDER BY. Truy vấn dưới đây giúp xác định vị trí của mỗi nhân viên trong bảng xếp hạng lương nội bộ:
SELECT
EmployeeID,
EmployeeName,
Department,
Salary,
RANK() OVER (
PARTITION BY Department
ORDER BY Salary DESC
) AS SalaryRank
FROM Employee;
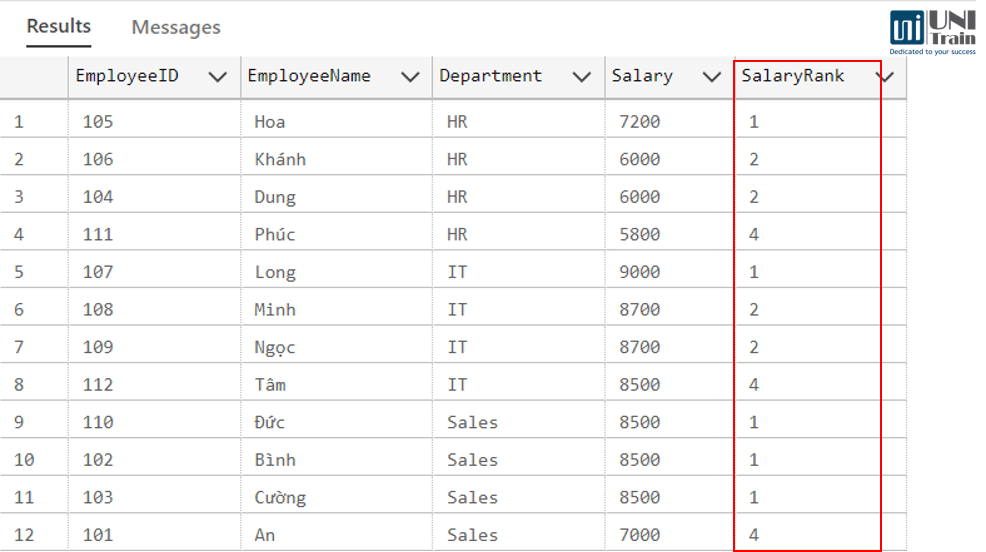
Kết quả truy vấn: Kết quả dưới đây thể hiện thông tin chi tiết của từng nhân viên, được sắp xếp theo thứ hạng mức lương trong phòng ban tương ứng.
Hàm DENSE_RANK()
DENSE_RANK() là một hàm xếp hạng trong SQL, giúp gán thứ tự liên tiếp cho các dòng dữ liệu trong cùng một nhóm, ngay cả khi có nhiều dòng cùng giá trị xếp hạng. Hàm này đặc biệt hữu ích trong các trường hợp cần duy trì thứ hạng tuần tự và rõ ràng, ví dụ như khi phân tích dữ liệu có cấu trúc phân cấp.
Hàm thường được sử dụng kết hợp với PARTITION BY để chia dữ liệu thành từng nhóm nhỏ trước khi thực hiện việc xếp hạng. Cách tiếp cận này giúp đảm bảo rằng việc phân loại và đánh giá dữ liệu diễn ra mạch lạc và có hệ thống.
Điểm khác biệt chính giữa DENSE_RANK() và RANK() nằm ở cách xử lý các giá trị trùng lặp. Nếu như RANK() bỏ qua một số thứ tự khi gặp các giá trị giống nhau, thì DENSE_RANK() lại duy trì thứ hạng liên tục, không tạo ra khoảng cách giữa các hạng. Điều này giúp kết quả phân tích dễ theo dõi và nhất quán hơn trong nhiều tình huống nghiệp vụ.
Cú pháp:
SELECT
column1,
column2,
DENSE_RANK() OVER (ORDER BY order_column1 [ASC or DESC],
order_column2 [ASC or DESC])
AS dense_rank_column
FROM
table_name;
Tham số
- DENSE_RANK(): Chính là hàm thực hiện việc xếp hạng theo thứ tự liên tục.
- PARTITION BY: Mệnh đề tùy chọn cho phép chia tập kết quả thành các nhóm riêng biệt. Việc xếp hạng sẽ được áp dụng riêng trong từng nhóm. Nếu không khai báo, toàn bộ tập dữ liệu sẽ được xử lý như một nhóm duy nhất.
- ORDER BY: Mệnh đề xác định cột (hoặc các cột) dùng để sắp xếp dữ liệu, qua đó quyết định thứ hạng của từng dòng trong kết quả.
Khi muốn truy vấn thứ hạng liên tục của các nhân viên theo mức lương trong từng phòng ban, bạn có thể sử dụng hàm DENSE_RANK() để đảm bảo các hạng được gán liền nhau mà không bỏ sót vị trí nào:
SELECT
EmployeeID,
EmployeeName,
Department,
Salary,
DENSE_RANK() OVER (
PARTITION BY Department
ORDER BY Salary DESC
) AS SalaryDenseRank
FROM Employee;
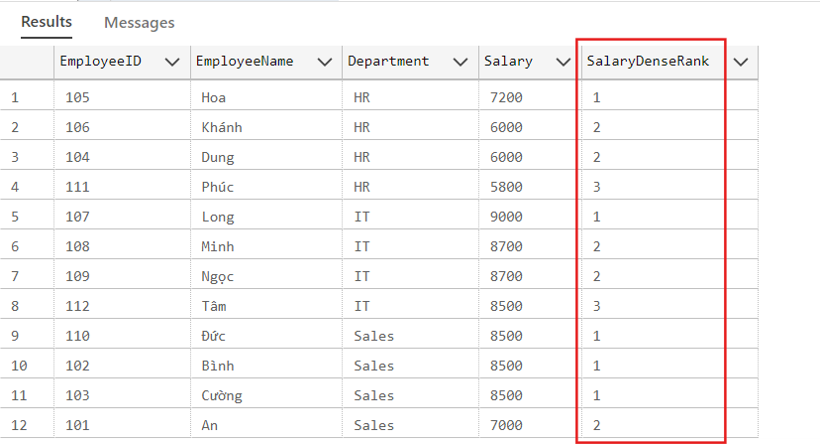
Kết quả truy vấn dưới đây hiển thị danh sách nhân viên kèm theo thứ hạng lương liên tục trong từng phòng ban, được xác định bằng hàm. DENSE_RANK():
So Sánh RANK() và DENSE_RANK()
| Tiêu chí | RANK() | DENSE_RANK() |
|---|---|---|
| Định nghĩa | Gán một thứ hạng duy nhất cho mỗi dòng, để lại khoảng trống giữa các hạng khi có giá trị bằng nhau. | Gán một thứ hạng duy nhất cho mỗi dòng, không có khoảng trống trong thứ hạng, ngay cả khi có giá trị bằng nhau. |
| Hành vi khi có giá trị bằng nhau | Bỏ qua (nhảy cóc) hạng tiếp theo sau khi có giá trị bằng nhau. Ví dụ: nếu hai dòng có cùng hạng 1, hạng kế tiếp sẽ là 3. | Không bỏ qua hạng nào sau khi có giá trị bằng nhau. Nếu hai dòng có cùng hạng 1, hạng kế tiếp sẽ là 2. |
| Ví dụ (không có giá trị bằng nhau) | Dữ liệu: 10, 20, 30, 40
Rank: 1, 2, 3, 4 |
Dữ liệu: 10, 20, 30, 40
Dense Rank: 1, 2, 3, 4 |
| Ví dụ (có giá trị bằng nhau) | Dữ liệu: 10, 20, 20, 30, 40
Rank: 1, 2, 2, 4, 5 |
Dữ liệu: 10, 20, 20, 30, 40
Dense Rank: 1, 2, 2, 3, 4 |
| Khoảng cách giữa các hạng | Xuất hiện khoảng trống trong dãy thứ hạng sau khi có giá trị bằng nhau. Ví dụ: sau khi có hạng 1 bị trùng, hạng 2 sẽ bị bỏ qua. | Không có khoảng trống trong dãy thứ hạng. Các dòng trùng hạng sẽ có cùng thứ hạng, và hạng kế tiếp sẽ liền kề. |
| Ảnh hưởng của việc bỏ qua hạng | Dẫn đến dãy hạng không liên tục khi có giá trị bằng nhau. | Duy trì dãy hạng liên tục mà không bỏ qua số nào, ngay cả khi có giá trị bằng nhau. |
| Ứng dụng | Hữu ích khi cần phân biệt rõ ràng các giá trị trùng nhau (ví dụ: trong thi đấu). | Lý tưởng khi cần duy trì dãy hạng liên tục, không bị gián đoạn. |
| Cú pháp | RANK() OVER (PARTITION BY ... ORDER BY ...) |
DENSE_RANK() OVER (PARTITION BY ... ORDER BY ...) |
Theo dõi Fanpage UniTrain để khám phá thêm nhiều thông tin hữu ích nhé.
Xem thêm
[KHÓA HỌC] Ứng dụng SQL trong xử lý dữ liệu
[KIẾN THỨC BỔ ÍCH] Phân biệt WHERE và HAVING trong SQL
[KIẾN THỨC BỔ ÍCH] SQL và các hàm xử lý kiểu dữ liệu Date thông dụng



