DAX đã cung cấp hai chức năng xếp hạng, gồm: RANK.EQ và RANKX. Hàm RANK thuộc nhóm Window Functions, dùng để xếp hạng dữ liệu trong một ngữ cảnh cụ thể. Hàm RANK sẽ giúp việc xếp hạng trên nhiều cột trở nên dễ dàng hơn, vì nó cung cấp tính năng sắp xếp thứ tự theo chiều được chỉ định trong một phân vùng xác định.
Ví dụ, người dùng sẽ làm tròn số tiền bán hàng lên bội số gần nhất của 400.000:
Rounded Sales = MROUND( [Sales Amount], 400000 ) |
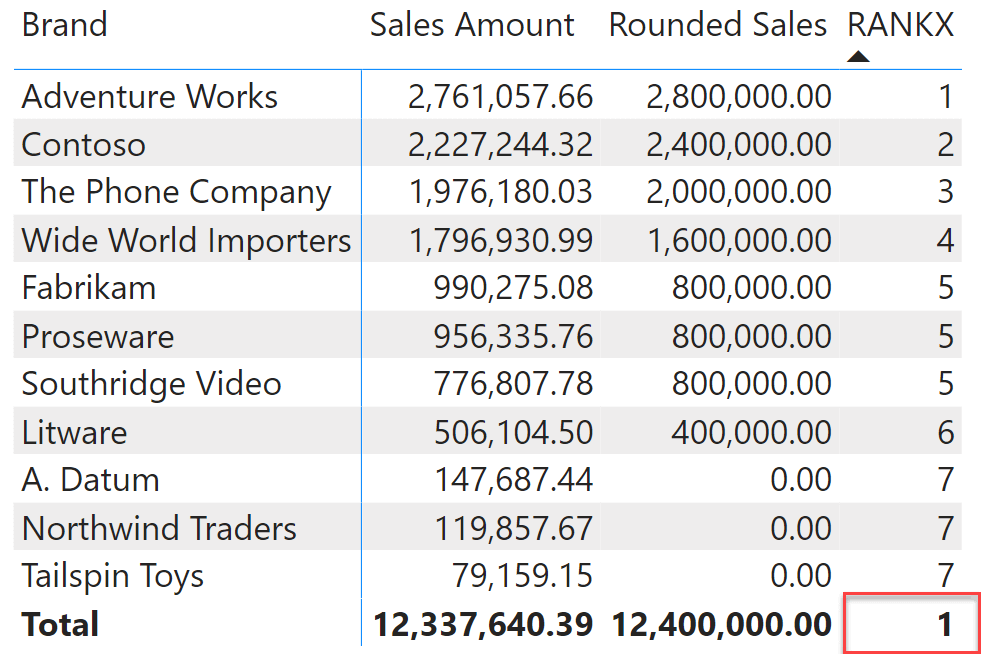
Công thức hàm RANKX khá pháp phức tạp và cần chú ý đến từng chi tiết. Công thức dưới đây, mặc dù đúng, nhưng vẫn có một vài nhược điểm để giải quyết đối với người mới dùng. Nếu người dùng muốn có xếp hạng dựa trên cột Product[Brand] bằng RANKX, thì hãy nhập mã dưới đây:
RANKX =RANKX ( ALLSELECTED ( 'Product'[Brand] ), [Rounded Sales], , DESC, DENSE )Kết quả hiển thị (như hình dưới):
Không chỉ hiển thị giá trị total mà giá trị subtotal (nếu có) cũng sẽ hiển thị cùng một kết quả (như hình dưới).
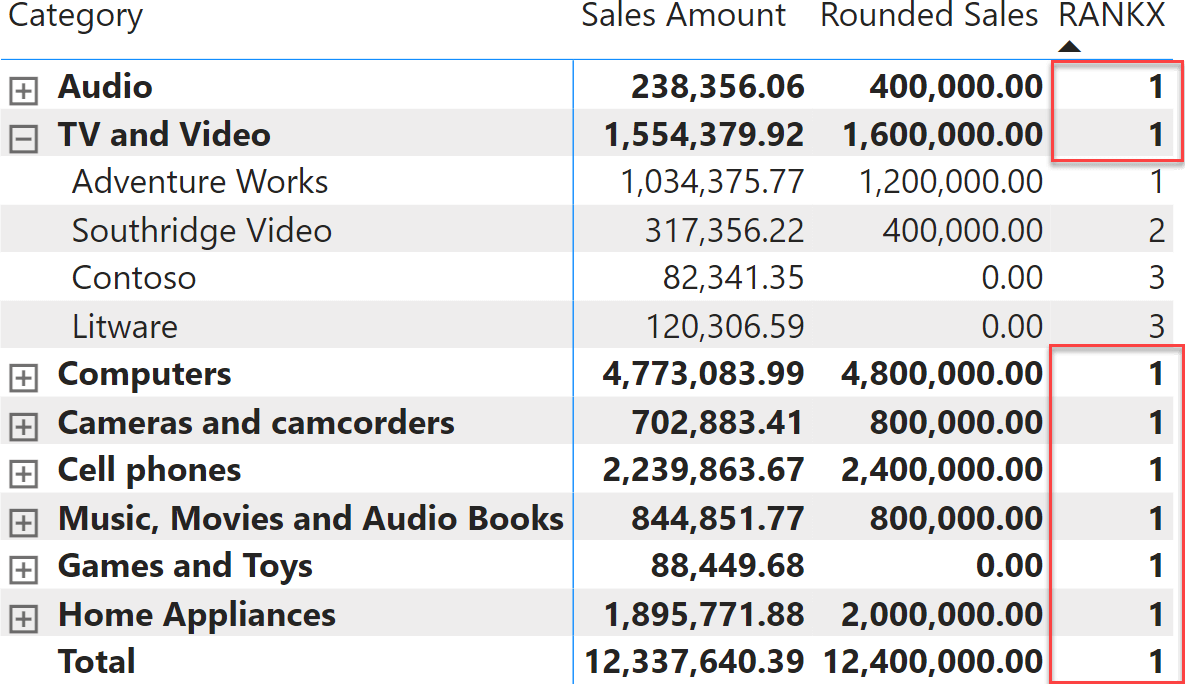
Bạn có thể giải quyết vấn đề này bằng cách sử dụng HASONEVALUE hoặc ISINSCOPE. Tuy nhiên, hãy lưu ý khi sử dụng hàm RANKX. Các mối quan hệ được xếp hạng như nhau bằng cách sử dụng RANKX, giống như Contoso và Litware (ở hình trên).
Ví dụ, người dùng muốn xếp hạng sự khác biệt giữa các mối quan hệ, chẳng hạn như sử dụng thứ tự chữ cái của thương hiệu làm thứ tự thứ hai cho xếp hạng:
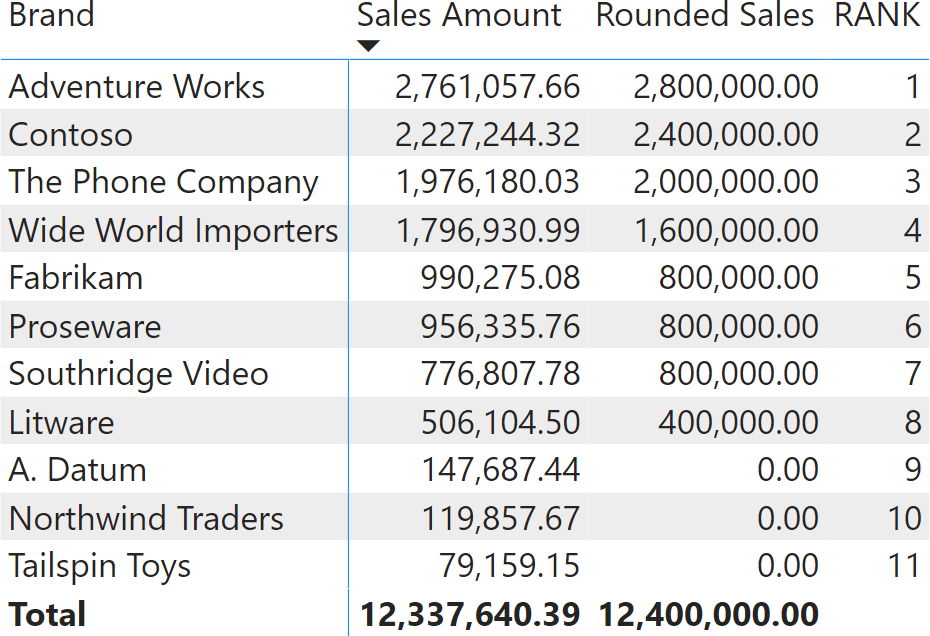
Để có được kết quả này thì cách thao tác vô cùng phức tạp và tốn thời gian. Trong khi đó, hàm RANK có thể giúp giải quyết vấn đề một cách đơn giản hơn. Với hàm RANK, bạn có thể cung cấp nhiều cột theo thứ tự với công thức của các window functions bằng cách nhập mã dưới đây:
RANK =RANK ( DENSE, ALLSELECTED ( 'Product'[Brand] ), ORDERBY ( [Rounded Sales], DESC, 'Product'[Brand], ASC )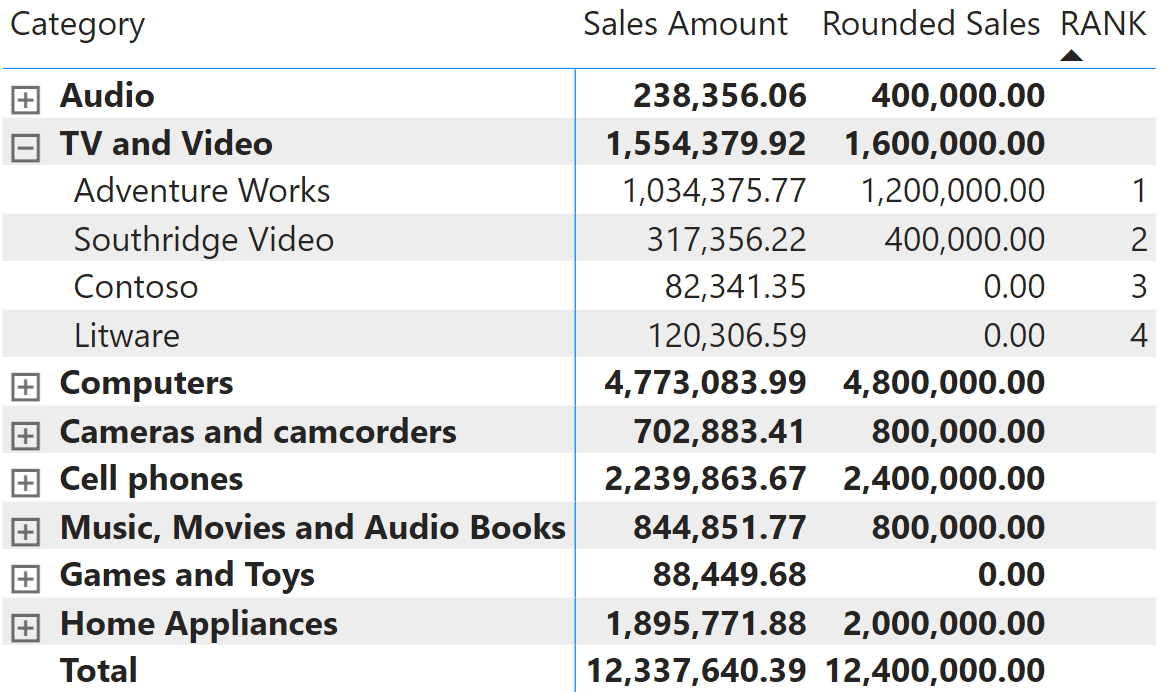
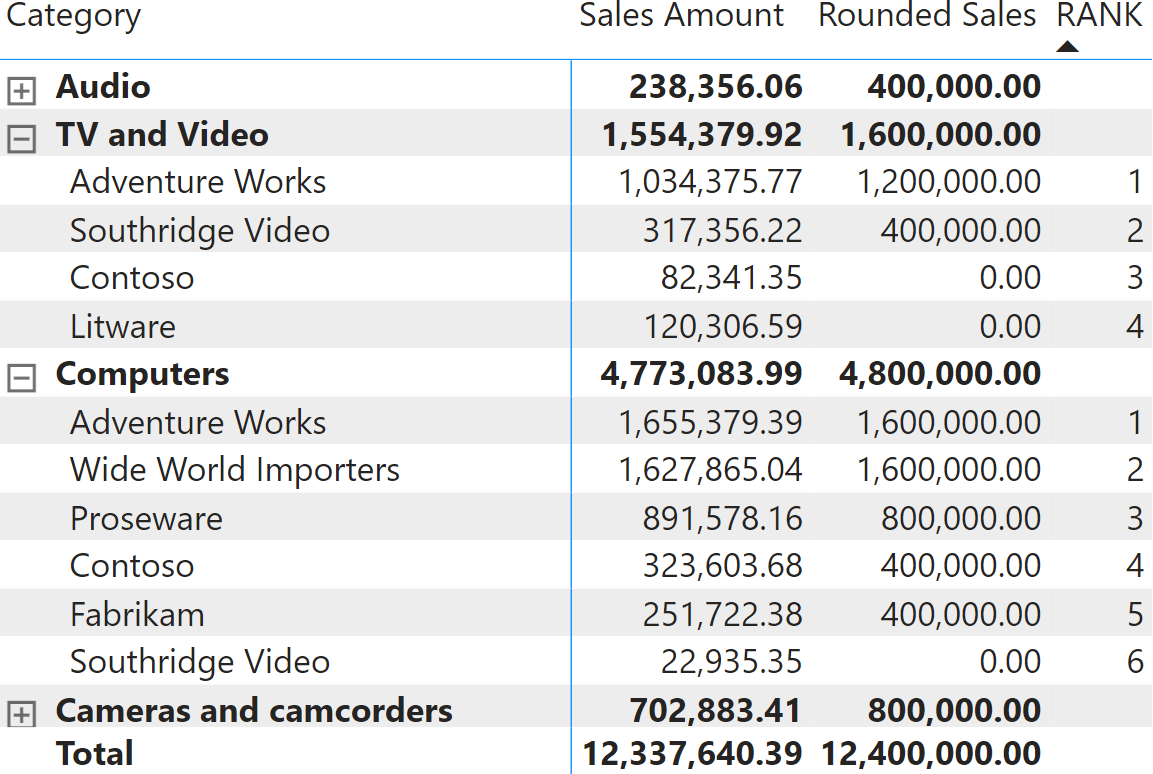
VAR SourceTable = ADDCOLUMNS ( ALLSELECTED ( Product[Brand] ), "@Amt", [Rounded Sales] )VAR Result = RANK ( DENSE, SourceTable, ORDERBY ( [@Amt], DESC, Product[Brand], ASC ) )RETURN ResultNếu mã dễ đọc hơn thì sẽ giúp người dùng hiểu rõ nội dung của bảng nguồn và cách tính cột được xếp hạng. Bằng cách xem nội dung của SourceTable, cột @Amt được tính trong bộ lọc hiện tại, trong đó cột duy nhất bị ẩn là Product[Brand]. Do đó, người dùng có thể biết được xếp hạng của các dữ liệu được lọc. Bằng cách mở rộng matrix để hiển thị nhiều danh mục, bạn có thể thấy xếp hạng luôn khởi động lại cho từng danh mục.
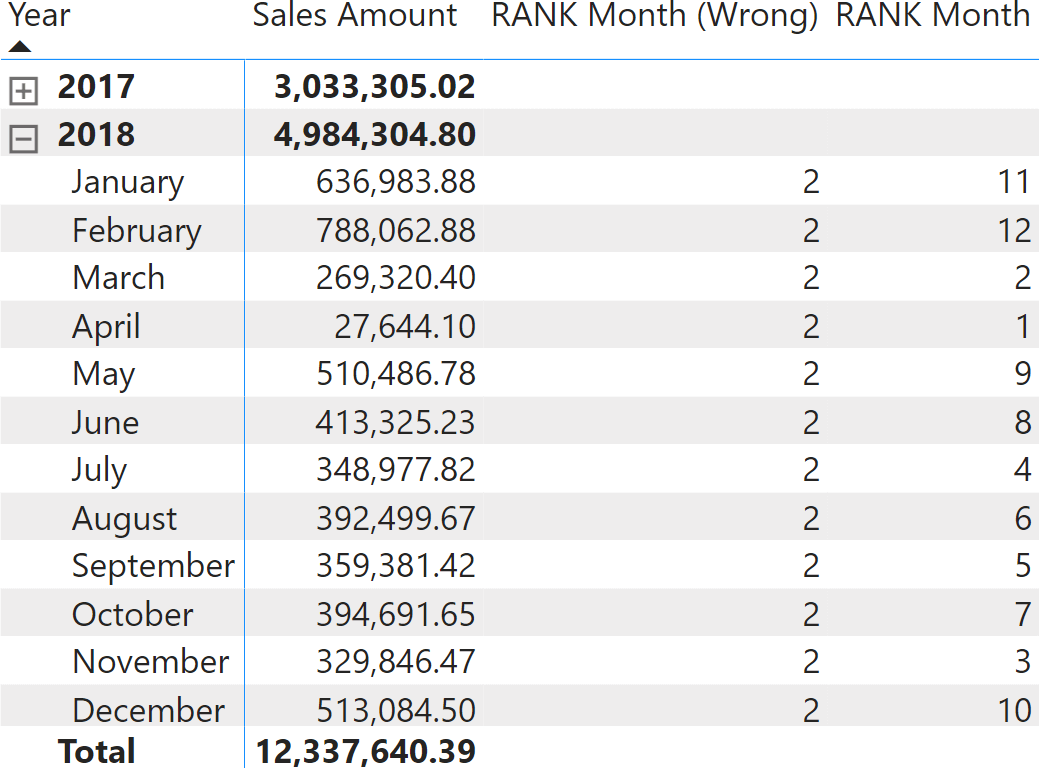
Ngoài ra, người dùng cần dự đoán các phần trong bộ lọc sẽ được thay thế khi đánh giá số lượng được sử dụng để xếp hạng để tránh một số rủi ro. Ví dụ, nếu người dùng xếp hạng các tháng với nhau mà nhập mã dưới đây sẽ không đúng:
RANK Month (Wrong) =VAR SourceTable = ADDCOLUMNS ( ALLSELECTED ( 'Date'[Month] ), "@Amt", [Sales Amount] )VAR Result = RANK ( DENSE, SourceTable, ORDERBY ( [@Amt] ) )RETURN Result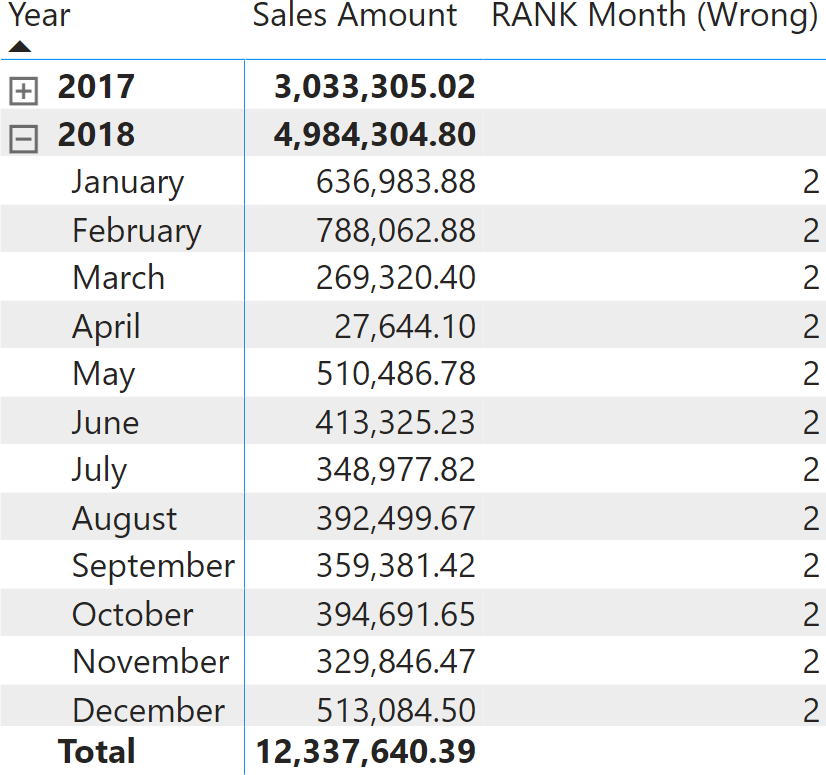
RANK Month =VAR SourceTable =ADDCOLUMNS (ALLSELECTED ('Date'[Month],'Date'[Month Number]),"@Amt", [Sales Amount])VAR Result =RANK (DENSE,SourceTable,ORDERBY ( [@Amt] ))RETURNResult