
Dữ liệu thiếu là một vấn đề phổ biến trong phân tích dữ liệu, nó ảnh hưởng đến tính chính xác và hiệu quả của quy trình phân tích hay các mô hình học máy. Thiếu dữ liệu có thể xảy ra do nhiều nguyên nhân như lỗi nhập liệu, thu thập dữ liệu không đầy đủ, hoặc do bản chất của dữ liệu.
Xử lý dữ liệu thiếu là một bước quan trọng trong việc chuẩn bị dữ liệu cho quy trình phân tích hay xây dưng các mô hình học máy. Trong bài viết này, UniTrain sẽ giới thiệu các phương pháp phổ biến để xử lý dữ liệu thiếu trong Python, bao gồm:
– Xóa bỏ: Phương pháp này loại bỏ các bản ghi dữ liệu có giá trị bị thiếu.
– Thay thế: Phương pháp này thay thế các giá trị thiếu bằng một giá trị khác, ví dụ như giá trị trung bình, trung vị, hoặc một giá trị mặc định.
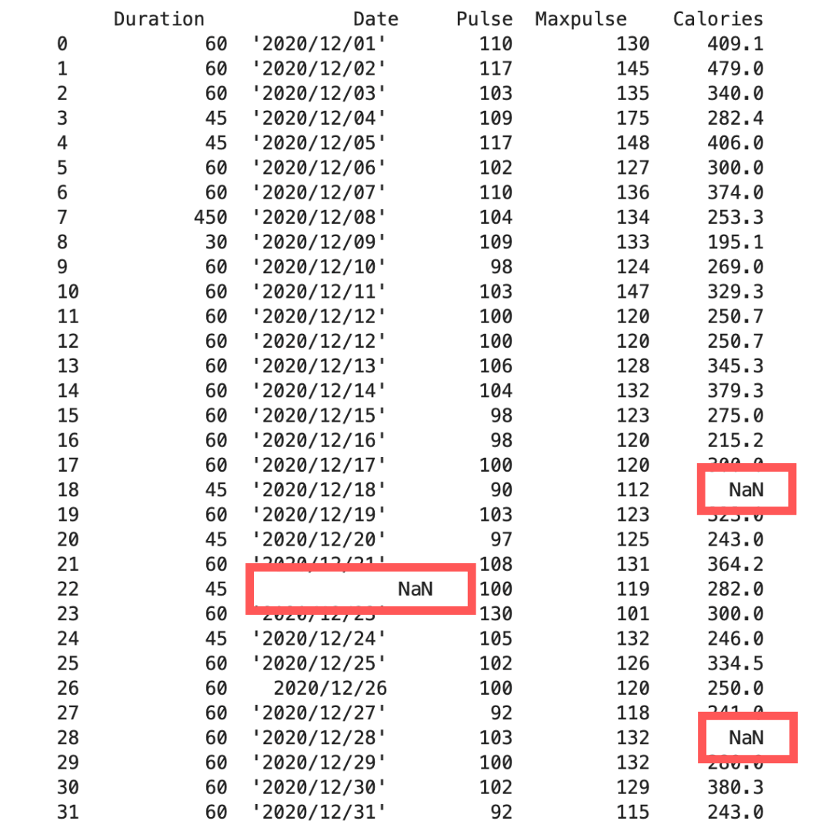
Bộ dữ liệu gốc
Đầu tiên, chúng ta sẽ tiến hành import dữ liệu:
import pandas as pd
df = pd.read_csv(‘data.csv’)
print(df)
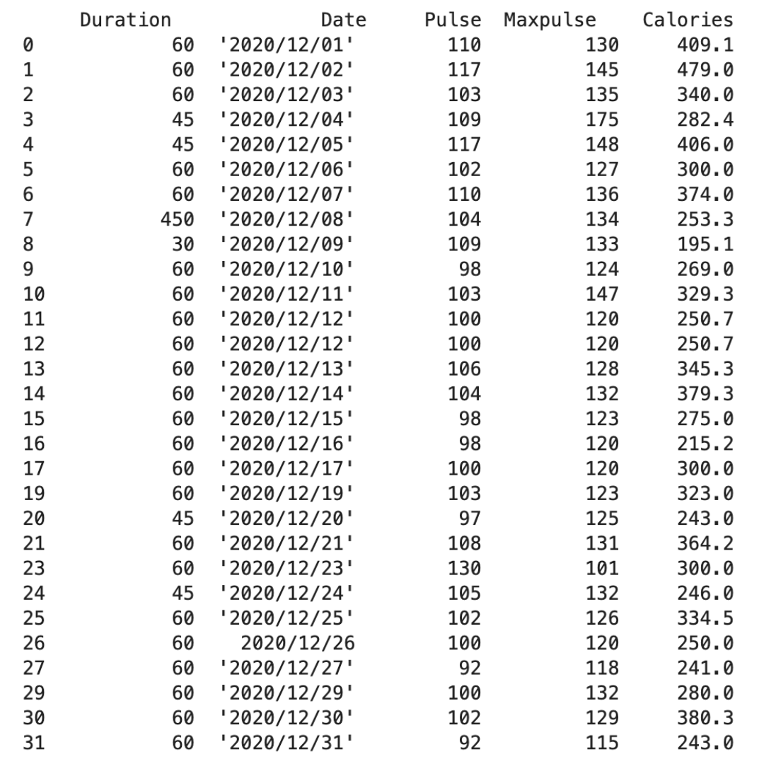
1. Loại bỏ dữ liệu thiếu
Một cách để xử lý các ô trống là loại bỏ những hàng chứa các ô trống đó.
Thông thường thì đây là cách có thể chấp nhận được, vì bộ dữ liệu rất lớn và việc loại bỏ một vài hàng sẽ không ảnh hưởng đáng kể đến kết quả.
new_df = df.dropna()
print(new_df)
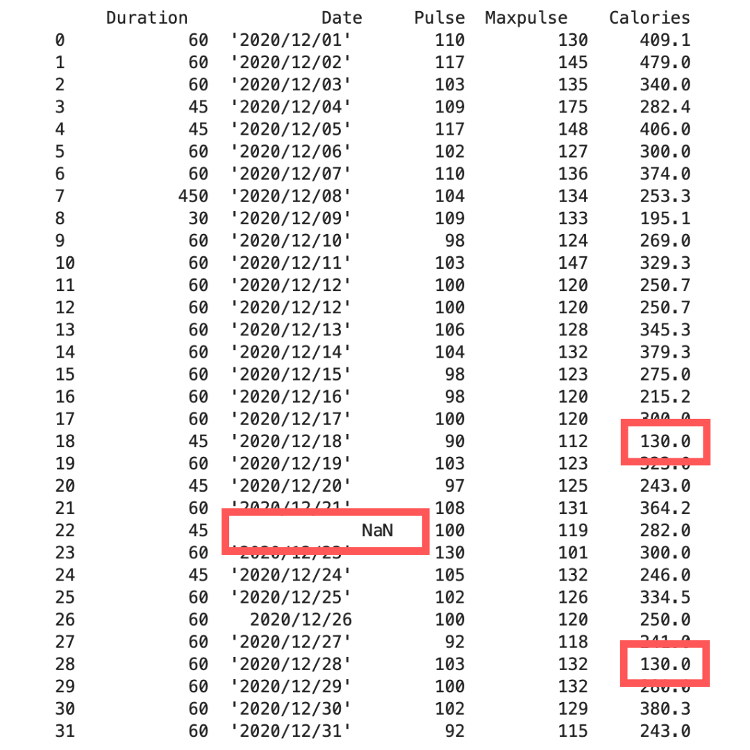
2. Thay thế tất cả các giá trị thiếu bằng một giá trị nhất định
Một cách khác để xử lý các ô trống là thay thế chúng bằng giá trị mới.
Bằng cách này, bạn không cần phải xóa toàn bộ các hàng chỉ vì một vài ô trống.
Câu lệnh fillna() cho phép chúng ta thay thế các ô trống bằng một giá trị cụ thể.
df.fillna(130, inplace = True)
print(df)
Lưu ý: Theo mặc định, phương thức dropna() trả về một DataFrame mới và không thay đổi DataFrame gốc.
Nếu bạn muốn thay đổi DataFrame gốc, hãy sử dụng đối số inplace=True.
– inplace=False (mặc định): Phương thức dropna() sẽ tạo và trả về một DataFrame mới, loại bỏ các hàng chứa giá trị thiếu. DataFrame gốc vẫn giữ nguyên.
– inplace=True: Phương thức dropna() sẽ loại bỏ các hàng chứa giá trị thiếu trực tiếp trên DataFrame hiện có, thay đổi chính DataFrame đó.

3. Thay thế giá trị thiếu của một cột bằng một giá trị nhất định
Để chỉ thay thế các giá trị trống cho một cột, hãy chỉ định tên cột của DataFrame
df[“Calories”].fillna(130, inplace = True)
print(df)
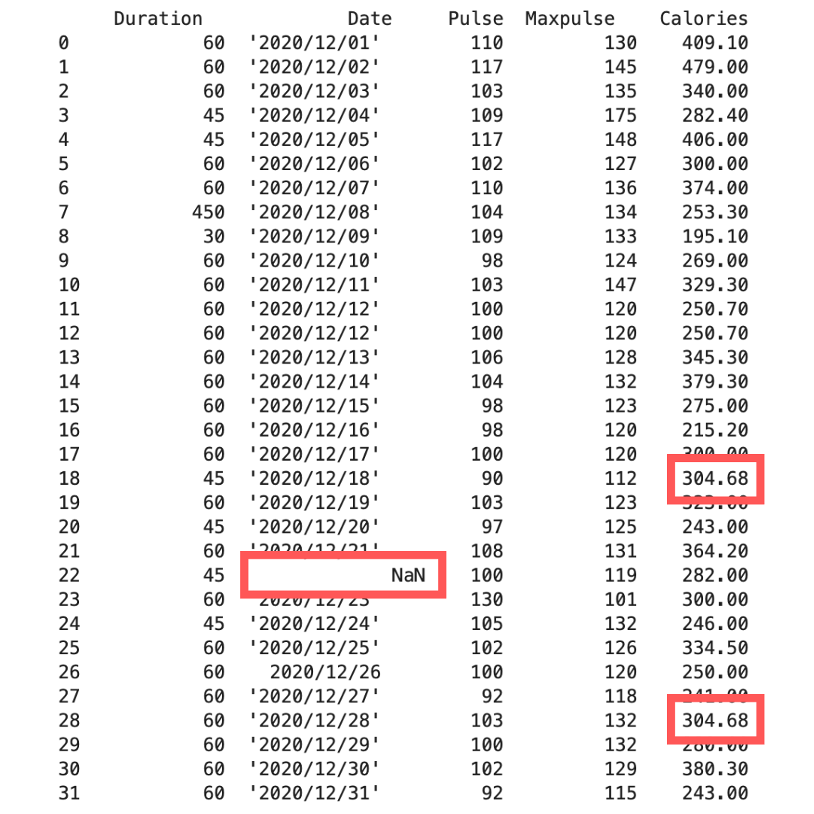
4. Thay thế giá trị thiếu bằng giá trị trung bình (mean), trung vị (median) hoặc mốt (mode)
Một cách phổ biến để xử lý các ô trống là tính toán giá trị trung bình, trung vị hoặc mốt của cột.
Thư viện Pandas cung cấp các hàm mean(), median(), và mode() để tính toán tương ứng các giá trị trung bình, trung vị và mốt cho một cột được chỉ định.
– Trung bình (mean()): Giá trị trung bình là tổng của tất cả các giá trị trong cột chia cho số lượng giá trị.
– Trung vị (median()): Trung vị là giá trị nằm chính giữa khi tất cả các giá trị trong cột được sắp xếp theo thứ tự tăng dần.
– Mốt (mode()): Mốt là giá trị xuất hiện nhiều nhất trong cột.
Sử dụng các phương thức này, bạn có thể thay thế các ô trống trong một cột bằng giá trị trung bình, trung vị hoặc mốt được tính toán từ các giá trị hợp lệ trong chính cột đó.
4.1 Thay thế giá trị thiếu bằng giá trị trung bình (mean)
x = df[“Calories”].mean()
df[“Calories”].fillna(x, inplace = True)
print(df)
4.2 Thay thế giá trị thiếu bằng trung vị (median)
x = df[“Calories”].median()
df[“Calories”].fillna(x, inplace = True)
print (df)
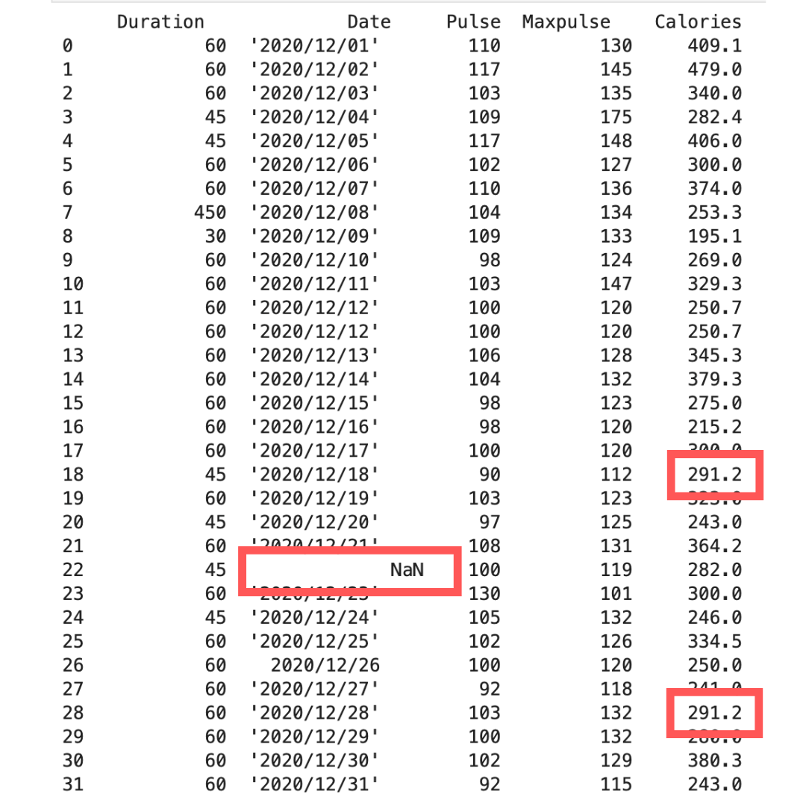
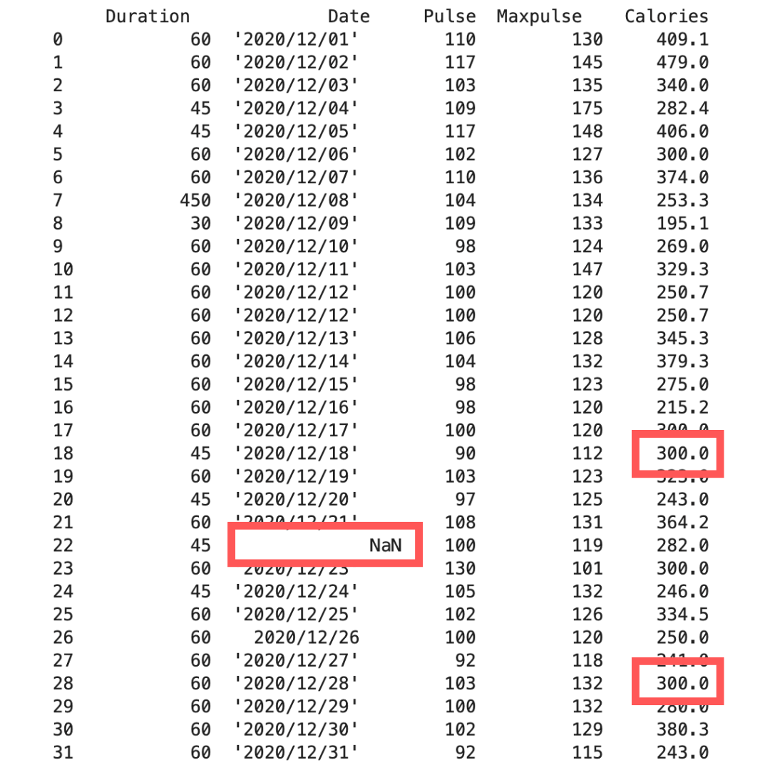
4.3 Thay thế giá trị thiếu bằng mốt (mode)
x = df[“Calories”].mode()[0]
df[“Calories”].fillna(x, inplace = True)
print(df)
Xem thêm:
Các hàm toán học trong thư viện Numpy